Batch spesifikasjonen
JSR 352 - Jakarta Batch spesifikasjonen
Jakarta Batch, tidligere kjent som Java Batch, er en del av Jakarta EE som gir en spesifikasjon for utføring av batchjobber i Jakarta EE-applikasjoner.
Jakarta Batch spesifiserer et Java API pluss et XML-basert jobbspesifikasjonsspråk (JSL) som lar deg sette sammen batchjobber i XML fra gjenbrukbare Java-applikasjonsartefakter og enkelt parametrisere forskjellige utførelser av en enkelt jobb.
Denne spesifikasjonen beskriver jobbspesifikasjonsspråket, Java-programmeringsmodellen, og kjøretidsmiljøet for Jakarta Batch. Den er designet for bruk på Jakarta EE-plattformimplementeringer og i Java SE-miljøer.
Jobs
I JSR 352 er en "Job" (jobb) en enhet som innkapsler en hel batchprosess, dvs. det er ganske enkelt en beholder for steg (som behandles lenger ned under overskriften Steps). En job kombinerer flere steg som hører logisk sammen i en flyt og gir mulighet for konfigurasjon av egenskaper globalt for alle steg, for eksempel omstartbarhet.
Jobbkonfigurasjonen inneholder:
- Navnet på jobben
- Definisjon og rekkefølge av steg
- Hvorvidt jobben er omstartbar eller ikke
Her er et eksempel fra Batch repoet under FS-Plattform.
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<job xmlns="http://xmlns.jcp.org/xml/ns/javaee" id="folkeregister" version="1.0">
<properties>
<property name="eierinstitusjonsnummer" value="#{jobParameters['eierinstitusjonsnummer']}"/>
<property name="jobbtype" value="#{jobParameters['jobbtype']}"/>
<property name="scope" value="OFFENTLIG_UTEN_HJEMMEL"/>
<property name="startdato" value="#{jobParameters['startdato']}"/>
</properties>
<step id="folkeregisterSynkroniser">
<chunk item-count="50">
<reader ref="folkeregisterItemReader"/>
<processor ref="#{jobParameters['jobbtype']}Processor"/>
<writer ref="#{jobParameters['jobbtype']}Writer"/>
</chunk>
</step>
</job>
Trinnene for å sette opp en Job
- Opprett en Batch Job XML-fil:
Denne filen, også kjent som en jobbspesifikasjonsfil, beskriver trinnene som batchjobben vil utføre. Det må være en gyldig XML-fil og følge Job Specification Language (JSL) definert av Jakarta Batch. Her er et grunnleggende eksempel:
<job id="myJob" xmlns="http://xmlns.jcp.org/xml/ns/javaee" version="1.0">
<step id="myStep">
<chunk>
<reader ref="myItemReader"/>
<processor ref="myItemProcessor"/>
<writer ref="myItemWriter"/>
</chunk>
</step>
</job>
- Opprett Batch Job Artefakter:
I XML-filen refererte vi tilmyItemReader,myItemProcessor, ogmyItemWriter. Dette er Java-klasser som definerer hvordan man leser data, behandler data og skriver ut resultatet av prosesseringen av disse data. Disse artefakter må implementeres i henhold til Jakarta Batch-spesifikasjonen.
@Named("myItemReader")
public class MyItemReader extends AbstractItemReader { /*...*/ }
@Named("myItemProcessor")
public class MyItemProcessor implements ItemProcessor { /*...*/ }
@Named("myItemWriter")
public class MyItemWriter extends AbstractItemWriter { /*...*/ }
- Start Batch Jobben:
For å starte batchjobben, må du få en referanse tilJobOperator-grensesnittet, som gir metoder for å kontrollere og administrere batchjobber.
JobOperator jobOperator = BatchRuntime.getJobOperator();
long executionId = jobOperator.start("myJob", new Properties());
start-metoden tar ID-en til jobben (som skal matche ID-en i XML-filen) og et Properties-objekt som kan brukes til å sende parametere til jobben.
Husk å plassere batch job XML-filen i META-INF/batch-jobs-mappen til applikasjonen din. Jakarta Batch-runtime vil se etter jobb XML-filer på dette stedet.
Dette er en forenklet forklaring på hvordan du setter opp en batchjobb i Jakarta Batch. Avhengig av bruksområdet ditt, må du kanskje håndtere mer komplekse scenarier, som å lage jobber med flere trinn, håndtere unntak, eller administrere transaksjoner.
Steps
Batchjobber består av steg (steps). Disse kan være av to ulike typer:
Batchlet steg
Av alle de fancy og kompliserte tingene du kan gjøre med en JSR-352 batchjobb, er batchlet det enkleste og beste stedet å starte. En batchlet er ganske enkelt et Java-program som kjøres for et steg. Programmet får kontroll, gjør hva det gjør, og så avsluttes det og trinnet er over.
Batchlet er en spesialisert komponent som er utformet for oppgaver som krever et enkelt utføringstrinn og passer spesielt godt for ikke-iterative oppgaver som å utføre opprydding, kjøre et frittstående skript eller initiere en enkelt datamigreringsoppgave.
Chunk steg
En chunk i batch-prosessering refererer til en avgrenset mengde data eller poster som leses inn, behandles og skrives ut som en enkelt transaksjon. En chunk er en liten delmengde av data som behandles som en enkelt enhet. Dataene leses inn én og én, men behandles i "chunks" eller segmenter innenfor en transaksjonsboundary.
For en batchlet får applikasjonskoden din bare kontroll én gang og gjør det den trenger å gjøre. Et chunk steg er annerledes fordi det alltid inneholder en løkke.
Et chunk-basert trinn er elementbasert. Så når vi ser på et chunk-basert trinn, forventer vi å behandle elementer individuelt.
Batch-containeren tar imot en liste med dataelementer og oppretter en løkke rundt kallene til applikasjonen din. Applikasjonen vil gjøre en del begrenset prosessering, kanskje på et enkelt dataelement, og deretter returnere elementet slik at containeren kan gå inn i neste runde i løkken og gjøre det samme om igjen på et nytt element.
Innenfor chunk steg er det tre hovedkomponenter. Disse tre komponentene speiler batchprosesseringens tretrinnsprosess som ble omhandlet tidligere:
- INPUT - innsamling av data gruppert i batcher
- PROSESSERING - behandling av de innsamlede data, én batch om gangen
- OUTPUT - med resultater i sekvensiell rekkefølge
- Item reader er ansvarlig for alle input til trinnet
- Item processor, som er valgfri, gir enhver ekstra transformasjon eller ytterligere validering eller tilleggslogikk som må brukes på hvert element
- Item writer gir output av dette steget
Et chunk-steg er rett og slett at batch-containeren kaller applikasjon om og om igjen i en løkke til du er ferdig. I teorien vil hvert pass gjennom løkken gjøre samme prosessering på de forskjellige dataelementene i listen av elementer den mottok.
Legg merke til løkken i sekvensdiagrammet under.
Her går løkken gjennom read() --> process(item) to ganger. Antall runder i løkken vil være avgrenset av hvor stor man har satt chunk størrelsen.
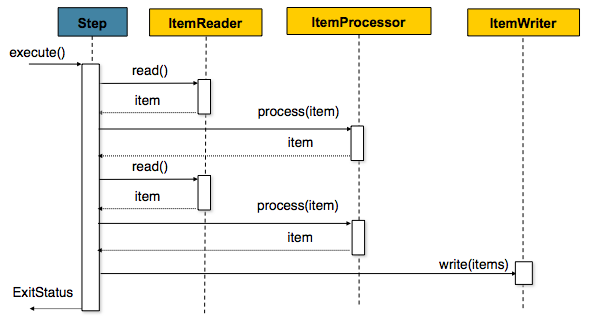 )
)
Legg også merke til at write(items) skjer én gang og det skjer etter at løkken er avsluttet.
Disse tre komponentene implementeres med hvert sitt interface
ItemReader interface
For å implementere en ItemReader må du vite hvordan du finner dataene du bruker som input til prosesseringsdelen av løkken. Det kan være i en databasetabell, en flat fil eller hvor som helst.
ItemReader har de følgende metodene:
open() er den første som får kontroll. Dette skjer bare én gang og det skjer utenfor løkken som danner chunk-steget. Dette er applikasjonens mulighet til å få tilgang til inndataene.
readItem() har kontroll over løkken. Når den returnerer null i stedet for et objekt, signaliseres det at batch-kjøringen er ferdig og løkken skal avsluttes.
close() vil bli kalt, som en del av det å avslutte løkken, for å lukke koblingen til datakilden.
checkPointInfo() kalles etter ItemReader sin readItem()-metode. Dataene som returneres av checkpointInfo() brukes til å markere et punkt etter at et visst antall elementer har blitt lest.
package jakarta.batch.api.chunk;
import java.io.Serializable;
/**
*
* ItemReader defines the batch artifact that reads
* items for chunk processing.
*
*/
public interface ItemReader {
/**
* The open method prepares the reader to read items.
*
* The input parameter represents the last checkpoint
* for this reader in a given job instance. The
* checkpoint data is defined by this reader and is
* provided by the checkpointInfo method. The checkpoint
* data provides the reader whatever information it needs
* to resume reading items upon restart. A checkpoint value
* of null is passed upon initial start.
*
* @param checkpoint specifies the last checkpoint
* @throws Exception is thrown for any errors.
*/
public void open(Serializable checkpoint) throws Exception;
/**
* The close method marks the end of use of the
* ItemReader. The reader is free to do any cleanup
* necessary.
* @throws Exception is thrown for any errors.
*/
public void close() throws Exception;
/**
* The readItem method returns the next item
* for chunk processing.
* It returns null to indicate no more items, which
* also means the current chunk will be committed and
* the step will end.
* @return next item or null
* @throws Exception is thrown for any errors.
*/
public Object readItem() throws Exception;
/**
* The checkpointInfo method returns the current
* checkpoint data for this reader. It is
* called before a chunk checkpoint is committed.
* @return checkpoint data
* @throws Exception is thrown for any errors.
*/
public Serializable checkpointInfo() throws Exception;
}
ItemProcessor interface
Det er valgfritt om du vil bruke ItemProcessor, du trenger ikke bruke denne komponenten. Dersom du ikke gjør det, blir objektene levert av ItemReader sendt rett til ItemWriter.
ItemProcessor har én metode:
processItem() tar seg av prosesseringen i løkken. Den får objektet som returneres av ItemReaders metode readItem(). Ta ut det du trenger fra dette objektet og gjør beregninger, kjør forretningsregler, summerer, sorter, eller beregne, hva enn du trenger for applikasjonen din. Når du er ferdig, trenger du bare å bestemme deg for én ting: Hva skal du returnere?
Det er helt opp til deg om du vil returnere noe eller ikke. Hvis du returnerer noe, vil det sendes til ItemWriter. Om du ikke returnerer noe, vil ItemWriter ikke vite noe om hva som har foregått i ItemProcessor. Kanskje prosesseringen betyr å lete etter visse typer poster, og hvis dette item ikke er en slik post, er det ingenting å fortelle til ItemProcessor og du kan returnere null.
package javax.batch.api.chunk;
/**
* ItemProcessor is used in chunk processing
* to operate on an input item and produce
* an output item.
*
*/
public interface ItemProcessor {
/**
* The processItem method is part of a chunk
* step. It accepts an input item from an
* item reader and returns an item that gets
* passed onto the item writer. Returning null
* indicates that the item should not be continued
* to be processed. This effectively enables processItem
* to filter out unwanted input items.
* @param item specifies the input item to process.
* @return output item to write.
* @throws Exception thrown for any errors.
*/
public Object processItem(Object item) throws Exception;
}
ItemWriter interface
ItemWriter blir kalt etter at løkken avsluttes ved at ItemReader leverer null og slik sier at alle elementer er lest.
En ItemWriter brukes altså til å skrive ut en liste av dataelementer for et chunk-steg i stedet for å skrive ut ett og ett element.
For noen datakilder kan det være mulig å gjøre bulkoppdateringer, der det er mer effektivt å skrive f.eks. fem rader samtidig i stedet for gjør dem én om gangen. Det er derfor løkken er strukturert på denne måten. Det lar ItemWriter dra nytte av disse mulighetene og skriv en haug med elementer på en gang.
ItemWriter har tre metoder:
open(checkpoint) blir kalt i samme transaksjon som ItemReader sin open(). Her kan du fortelle hvor data skal skrives hen og gir deg mulighet til å opprette en fil for output, åpne connection til en database eller lignende.
close() vil bli kalt i lag med ItemReader sin close() metode etter at løkken er avsluttet. Gjør hva som må gjøres for å avslutte skrivingen av data.
writeItems(items) skriver ut resultatet av prosesseringen. For hvert element, ble
read()ogprocess(item)utført. Objektet som ble returnert fraprocess(item), ble lagt i listen av items som først nå, når løkken er avsluttet, sendes inn iwrite(items).checkpointInfo() metoden kalles writeItems()-metoden. Dataene som returneres av checkpointInfo() brukes til å markere et punkt etter at et visst antall elementer har blitt skrevet. Hvis batchjobben må startes på nytt, kan den bruke disse sjekkpunktsdataene for å vite hvor den skal fortsette å skrive.
Java kildekode for ItemWriter interfacet
package javax.batch.api.chunk;
import java.io.Serializable;
import java.util.List;
/**
*
* ItemWriter defines the batch artifact that writes to a
* list of items for chunk processing.
*
*/
public interface ItemWriter {
/**
* The open method prepares the writer to write items.
*
* The input parameter represents the last checkpoint
* for this writer in a given job instance. The
* checkpoint data is defined by this writer and is
* provided by the checkpointInfo method. The checkpoint
* data provides the writer whatever information it needs
* to resume writing items upon restart. A checkpoint value
* of null is passed upon initial start.
*
* @param checkpoint specifies the last checkpoint
* @throws Exception is thrown for any errors.
*/
public void open(Serializable checkpoint) throws Exception;
/**
* The close method marks the end of use of the
* ItemWriter. The writer is free to do any cleanup
* necessary.
* @throws Exception is thrown for any errors.
*/
public void close() throws Exception;
/**
* The writeItems method writes a list of item
* for the current chunk.
* @param items specifies the list of items to write.
* @throws Exception is thrown for any errors.
*/
public void writeItems(List<Object> items) throws Exception;
/**
* The checkpointInfo method returns the current
* checkpoint data for this writer. It is
* called before a chunk checkpoint is committed.
* @return checkpoint data
* @throws Exception is thrown for any errors.
*/
public Serializable checkpointInfo() throws Exception;
package javax.batch.api.chunk;
import java.io.Serializable;
import java.util.List;
/**
* The AbstractItemWriter provides default implementations
* of not commonly implemented methods.
*/
public abstract class AbstractItemWriter implements ItemWriter {
/**
* Override this method if the ItemWriter requires
* any open time processing.
* The default implementation does nothing.
*
* @param last checkpoint for this ItemReader
* @throws Exception (or subclass) if an error occurs.
*/
@Override
public void open(Serializable checkpoint) throws Exception { }
/**
* Override this method if the ItemWriter requires
* any close time processing.
* The default implementation does nothing.
*
* @throws Exception (or subclass) if an error occurs.
*/
@Override
public void close() throws Exception { }
/**
* Implement write logic for the ItemWriter in this
* method.
*
* @param items specifies the list of items to write.
* @throws Exception (or subclass) if an error occurs.
*/
@Override
public abstract void writeItems(List<Object> items) throws Exception;
/**
* Override this method if the ItemWriter supports
* checkpoints.
* The default implementation returns null.
*
* @return checkpoint data
* @throws Exception (or subclass) if an error occurs.
*/
@Override
public Serializable checkpointInfo() throws Exception {
return null;
}
}
Oppsummering Chunk-orientert prosessering
JSR 352 spesifiserer en 'Chunk Oriented'-prosesseringsstil som sitt primære mønster. Chunk-orientert prosessering refererer til å lese dataene ett element om gangen, og lage "biter" som vil bli skrevet ut, innenfor en transaksjonsgrense. Ett element leses inn fra en ItemReader, leveres til en ItemProcessor og aggregeres. Når antallet leste elementer tilsvarer commit-intervallet, skrives hele delen ut via ItemWriter, og deretter blir transaksjonen avsluttet.
Chunk-orientert prosessering gir flere fordeler:
- Stabilitet ved behandling av store datasett ved å dele opp i mindre transaksjoner.
- Mulighet for gjenoppretting ved feil basert på antall behandlede poster.
- Effektiv minnehåndtering ved å unngå lasting av hele datasettet.
- Chunk-størrelsen kan konfigureres for å optimalisere ytelse og ressursbruk basert på jobbens natur og datasettets størrelse
Komplekse batchjobber
Jakarta Batch gir konstruksjoner for å lage mer komplekse batchjobber, som Flow Control, Conditional Execution, Split og Step Partitioning. Disse konstruksjonene gjør at du kan lage sofistikerte batchjobber som kan håndtere komplekse forretningskrav.
For å forstå bruken av hver av disse konstruksjonene må du fordype deg i spesifikasjonen.
Her er en kort beskrivelse av hver av dem:
-
Flow Control gir deg muligheten til å spesifisere rekkefølgen som trinnene utføres i en batchjobb. Som standard utføres trinn i den rekkefølgen de er står i jobb XML-filen. Du kan imidlertid overstyre dette ved å bruke
nextattributtet for å spesifisere neste trinn som skal utføres.Flow Control<step id="step1" next="step3"><!-- ... --></step><step id="step2" next="step4"><!-- ... --></step><step id="step3" next="step2"><!-- ... --></step><step id="step4"><!-- ... --></step>I dette eksempelet vil trinnene bli utført i følgende rekkefølge:
step1,step3,step2,step4. -
Conditional Execution gir deg muligheten til å kontrollere flyten av trinn basert på avslutningsstatusen til tidligere trinn.
decisionelementet brukes for dette. For eksempel:Conditional Execution<step id="step1" next="decision1"><!-- ... --></step><decision id="decision1" ref="myDecider"><end on="COMPLETED" exit-status="done"/><fail on="FAILED"/><next on="*" to="step2"/></decision><step id="step2"><!-- ... --></step>Her er
myDeciderenDeciderimplementasjon som setter avslutningsstatusen. Hvis avslutningsstatusen er "COMPLETED", avsluttes jobben. Hvis den er "FAILED", mislykkes jobben. For enhver annen status, fortsetter den tilstep2. -
Split gir deg muligheten til å utføre flere trinn samtidig.
splitelementet brukes for dette formålet. Hverflowinnenfor ensplitkan inneholde ett eller flere trinn og utføres uavhengig av andre flows. For eksempel:Split<split id="split1"><flow id="flow1"><step id="step1" next="step2"/><step id="step2"/></flow><flow id="flow2"><step id="step3" next="step4"/><step id="step4"/></flow></split>I dette eksempelet utføres
flow1(som inneholderstep1ogstep2) ogflow2(som inneholderstep3ogstep4) samtidig. -
Step Partitioning gjør det mulig å bryte ned en batch-jobb i mindre, håndterbare deler som kan kjøres parallelt for å forbedre ytelsen. Her er et eksempel på en XML-konfigurasjonsfil for batch-jobber som demonstrerer bruk av Step Partitioning
Step Partitioning<job id="myJob" xmlns="http://xmlns.jcp.org/xml/ns/javaee" version="1.0"><step id="myStep"><chunk item-count="5"><reader ref="myItemReader" /><processor ref="myItemProcessor" /><writer ref="myItemWriter" /></chunk><partition><mapper ref="myMapper"><properties><property name="partitions" value="3" /><property name="threads" value="2" /></properties></mapper><collector ref="Collector" /><analyzer ref="Analyzer" /><reducer ref="Reducer" /></partition></step></job>I dette eksempelet inneholder jobben
myJobet chunk step som er partisjonert.Det partisjonerte steget deles inn i 2 partisjoner, med 3 tråder som kjører samtidig som definert av Partition-mapperen
myMapper.Collector,Analyzer, ogReducerbrukes for å samle data fra hver partisjon, analysere de og deretter redusere de til et enkelt resultat.
Checkpoints
Checkpoints i Jakarta Batch (JSR-352) brukes til å lagre statusen til en kjørende batch-jobb med spesifikke intervaller. Dette gjør det mulig å restarte jobben fra siste sjekk-punkt i tilfelle feil eller avbrudd.
Checkpoint-policy
Checkpoints-policyen bestemmer når checkpoints skal tas under utførelsen av et chunk-steg. Det finnes tre alternativer:
-
Antall elementer: Checkpoints tas etter at et spesifisert antall elementer er behandlet. Dette konfigureres med attributten
item-countpå<chunk>-elementet. -
Tidsgrense: Checkpoints tas etter at et spesifisert tidsintervall har utløpt. Dette konfigureres med attributten
time-limitpå<chunk>-elementet. -
Tilpasset: En tilpasset checkpoints-algoritme kan implementeres ved å gi en klasse som implementerer grensesnittet
CheckpointAlgorithm. Dette konfigureres med attributtenecheckpoint-policy="custom"ogcheckpoint-algorithmpå<chunk>-elementet.
Checkpoints-data
Når et checkpoint utløses, kaller batch-kjøringsmiljøet metoden checkpointInfo() på implementasjonene av ItemReader og ItemWriter for å hente checkpoint-data. Disse dataene bør inneholde nok informasjon til å kunne restarte ItemReader og ItemWriter fra det nåværende punktet ved behov.
Checkpoint-dataene lagres i jobb-repositoriet, sammen med annen jobb-metadata, for å sikre at de er trygt lagret.
Restarte fra et checkpoint
Hvis en jobb mislykkes eller avbrytes, kan den startes på nytt fra siste checkpoint. Under omstart henter batch-kjøringsmiljøet checkpoint-dataene fra jobb-repositoriet og sender dem til ItemReader og ItemWriter sine open()-metoder. Dette gjør at ItemReader og ItemWriter kan gjenopprette sin tilstand og fortsette prosesseringen fra der de slapp.
Andre tema i spesifikasjonen
Det er flere tema man må dykke ned i når man vil utvikle en batchapplikasjon i Jakarta Batch. Vi vil kort nevne noen av dem og du oppfordres til å dukke ned i disse temaene i dokumentene Understanding Java Batch og Batch Applications for the Java Platform som er omtalt under overskriften Batch - Om denne veilederen
Når noe går galt
Det er alltid noe, enten det er dårlige inndata, noe som er feil konfigurert, feil i applikasjonskoden, noens dårlige antagelse eller noe annet. Ting går galt.
Batch Status
Batch-runtime vil opprettholde en status for jobben og for hvert trinn. Det er definert flere mulige statuser for en batchjobb:
- STARTED: Jobben har startet vellykket, men er ikke ferdig ennå.
- STOPPING: En stoppforespørsel har blitt utstedt for jobben, men den er ennå ikke fullstendig stoppet.
- STOPPED: Jobben har stoppet. Det kan skyldes en eksplisitt stoppforespørsel eller en uventet feil.
- FAILED: Jobben mislyktes i å fullføre vellykket. Årsaken kan være en unntakssituasjon eller uventet feil.
- COMPLETED: Jobben har fullført vellykket.
- ABANDONED: Jobben har blitt forlatt. Denne statusen brukes ofte når en jobb ikke kan startes på nytt etter en feil.
- STARTING: Jobben er i ferd med å starte, men har ikke offisielt startet ennå.
- COMPLETING: Jobben er i ferd med å fullføre, men har ikke offisielt fullført ennå.
- UNKNOWN: Jobbstatusen er ukjent. Dette er typisk en systemfeil der jobbens status ikke kan bestemmes.
Disse statusene gir deg en ide om hvor jobben er i livssyklusen. Du kan bruke denne informasjonen for feilhåndtering, rapportering, eller for å ta beslutninger i applikasjonen din.
I tillegg har vi Exit Status som er en egendefinert streng som du kan sette for å gi tilleggsinformasjon om resultatet av en jobb eller et trinn. I motsetning til Batch Status, som er definert av batch-runtime og har et begrenset sett med forhåndsdefinerte statuser, er Exit Status brukerdefinert og kan være hvilken som helst streng. Det kan brukes til å gi mer spesifikk informasjon om slutten på en jobb eller et trinn enn Batch Status alene.
For eksempel kan du sette exit status til 'DATA_VALIDATION_FAILED' hvis en jobb mislykkes på grunn av ugyldige data. Dette lar deg differensiere fra andre typer feil (som 'IO_ERROR') som kan ha sine egne exit statuser.
Exception Handling
I Jakarta Batch er unntakshåndtering en viktig del av batchbehandling. Hvis det oppstår et unntak under utførelsen av en batchjobb, endrer batch-runtime batch-status til FAILED og transaksjonen rulles tilbake.
I tilfeller der du ønsker spesifikk feilhåndtering, gir Jakarta Batch en catch-attributt i Job Specification Language (JSL). Denne attributten lar spesifikke trinn bli utført når et unntak blir kastet.
Jakarta Batch gir også retry og skip-elementer i JSL for å håndtere unntak. Retry-elementet angir hvilke unntak som skal føre til at en chunk prøves på nytt. Skip-elementet angir hvilke unntak som skal føre til at en chunk blir hoppet over.
Det er enda et unntakshåndteringsalternativ som kalles retryable-exception-classes. Unntak som er oppført i her håndteres også via gjenopptaksbehandling, men hele denne chunk vil bli prøvd kjørt på nytt.
Listeners
I Jakarta Batch gir Listeners en måte å inkludere tilpasset kode som kan reagere på bestemte hendelser i løpet av en batchjobs livssyklus. Listeners lar deg utføre oppgaver som logging, varsler, oppsett og opprydding på bestemte punkter i jobbprosesseringen.
- Job Listeners: Reagerer på hendelser på jobb-nivå
- Step Listeners: Reagerer på hendelser på steg-nivå
- Chunk Listeners: Reagerer på hendelser på chunk-nivået
- Item Listeners: Reagerer på hendelser relatert til lesing, behandling og skriving av individuelle elementer
Parameters, Properties og Contexts
I Jakarta Batch brukes Parameters, Properties og Contexts til å styre og gi informasjon om batchbehandling.
-
Parameters: Disse er brukerdefinerte og blir sendt til jobber eller steg ved utførelsestidspunktet. De kan brukes til å tilpasse oppførselen til en jobb eller et steg.
-
Properties: Disse er lik parametere, men de er definert i Job Specification Language (JSL) filen selv. De kan brukes til å konfigurere batch-artefakter som Readers, Processors og Writers.
-
Contexts: Disse blir levert av batch-runtime og inneholder informasjon om kjøre-miljøet. Det er to typer kontekster: JobContext og StepContext. Disse kontekstene gir metoder for å få tilgang til jobbrelatert data som jobbparametere, batch-status og exit-status.
Restarte en mislykket jobb
Gjenopptak av en mislykket jobb er en avgjørende funksjon i batchbehandling. I Jakarta Batch (JSR-352) tillater det en mislykket jobb å gjenoppta fra omtrent der den stoppet. Denne funksjonaliteten er ikke automatisk og krever nøye vurdering når du skriver applikasjonen din. Visse aspekter må implementeres riktig for å sikre at restartprosessen fungerer som forventet.