Supergraf
I supergrafen presenteres dataene i ett samlet API. Dette gjør det mulig for konsumenter å hente og kombinere data fra forskjellige datakilder, eller subgrafer, gjennom ett sentralisert endepunkt. Dermed trenger ikke konsumentene å forholde seg til flere endepunkter for å finne fram til- og hente data.
Med supergrafen kan migrering av data gjøres uten at konsumentene trenger å forholde seg til det. For eksempel kan data flyttes fra å ligge i FS til å ligge i Utdanningsregisteret, men fortsatt framstå som uendret i supergrafen. Ved innføring av nye datakilder/subgrafer, kan data fra disse legges til i supergrafen uten at konsumentene trenger å integrere mot et nytt endepunkt.
Per i dag er følgende subgrafer inkludert:
Tilgjengelighet og kildekode
Supergrafendepunktet er basert på Hive Gateway og kjører i Platon PaaS. Gatewayen er ansvarlig for å rute GraphQL-spørringer til de ulike subgrafenes endepunkter, basert på Apollo Federation 2-protokollen. Supergrafskjemaet hentes fra skjemaregisteret Hive Schema Registry og blir automatisk oppdatert med endringer som skjer der ved publisering av subgrafskjema til supergraf.
Supergrafendepunktet er tilgjengelig i flere miljøer:
| Miljø | URL |
|---|---|
| TEST | https://supergraf-gateway-test.fsweb.no/graphql |
| DEMO | TBA |
| PROD | TBA |
Kildekoden til supergrafen ligger i supergraf-repoet på GitLab.
Hvordan gjøre en datakilde/subgraf til en del av supergrafen
For å bli en del av supergrafen er du nødt til å oppfylle kravene under og inkludere skjemasjekking og publisering som en del av din pipeline. En subgraf blir automatisk inkludert når man bruker skjemasjekking og publiseringsfunksjonaliteten.
Krav:
- URL til subgraf-API - et endepunkt som svarer på GraphQL-spørringer for subgrafen
- GraphQL-skjemafil som representerer subgrafen
- Sette opp hjelpe-jobber i CI/CD pipeline
Håndtering av endringer i subgraf
For å påse at endringer i en subgraf er trygge og ikke skaper uventede problemer i supergrafen er det laget GitLab CI/CD-jobber som kan brukes i pipeline for å automatisk sjekke og publisere trygge skjemaendringer.
Hjelpejobbene ligger her med dokumentasjon om hvordan de kan brukes.
Prosessen som disse jobbene representerer er todelt:
- Sjekker subgrafskjema for feil og brekkende endringer
- Publisering av subgrafskjema til supergraf
1 Sjekker subgrafskjema for feil og brekkende endringer
Ved opprettelse av MR blir det kjørt en schema check gjennom Hive - schema registry.
Ved feil i skjemaet eller brekkende endringer vil man se at feilene blir presentert i GitLab som en kommentar på MR-en. Feilene kan også sees sammen med schema diff m.m. i Hive sitt webgrensesnitt*. Dersom en MR fører til skjemaendringer som gir composition errors, altså at skjemaet er ugyldig fordi det inneholder syntaksfeil, eller mer relevant fordi det ikke er kompatibelt med en annen subgraf, så vil pipelinen knekke og bli rød. MR-en ikke kunne merges før dette er rettet.
Resultat fra skjemasjekk i form av kommentar i merge request ser slik ut:
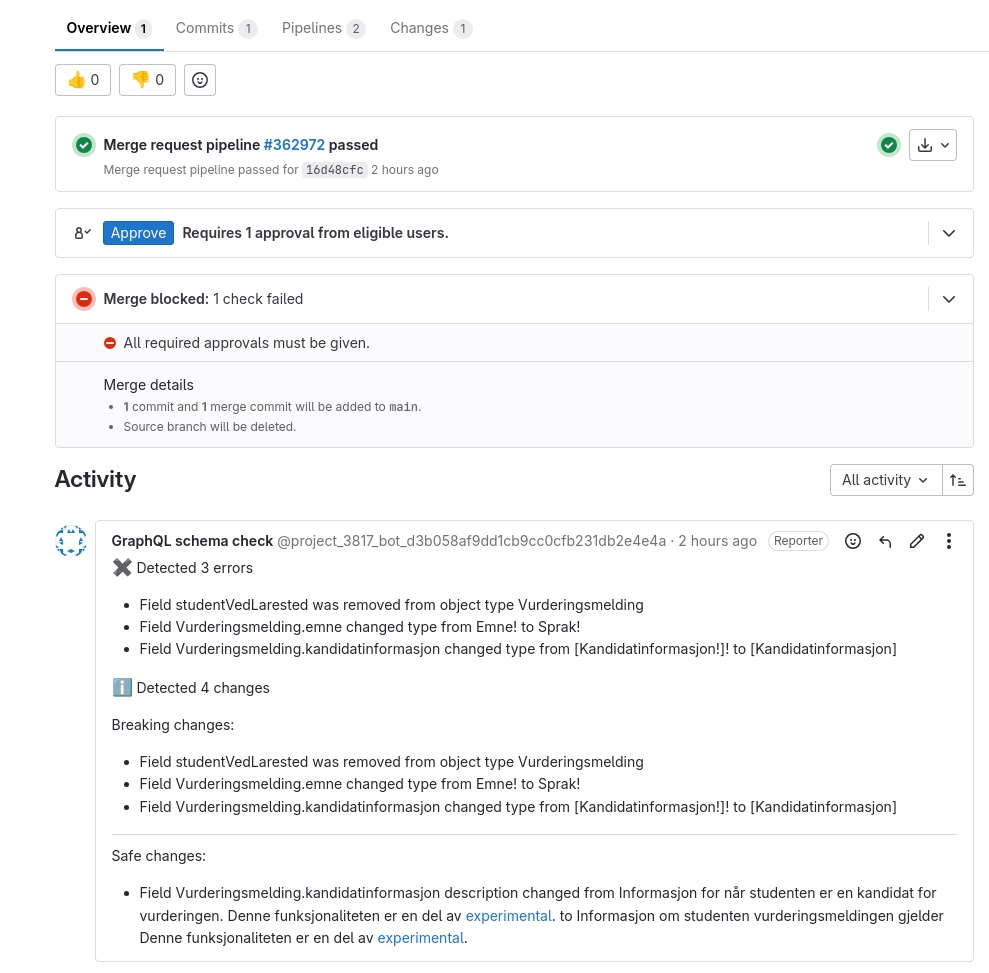
Man kan også se feilene i loggen til skjemasjekk-jobben og mer informasjon i Hive sitt grensesnitt. For å navigere deg dit må du klikke på lenken som vises
i jobbens log-output. 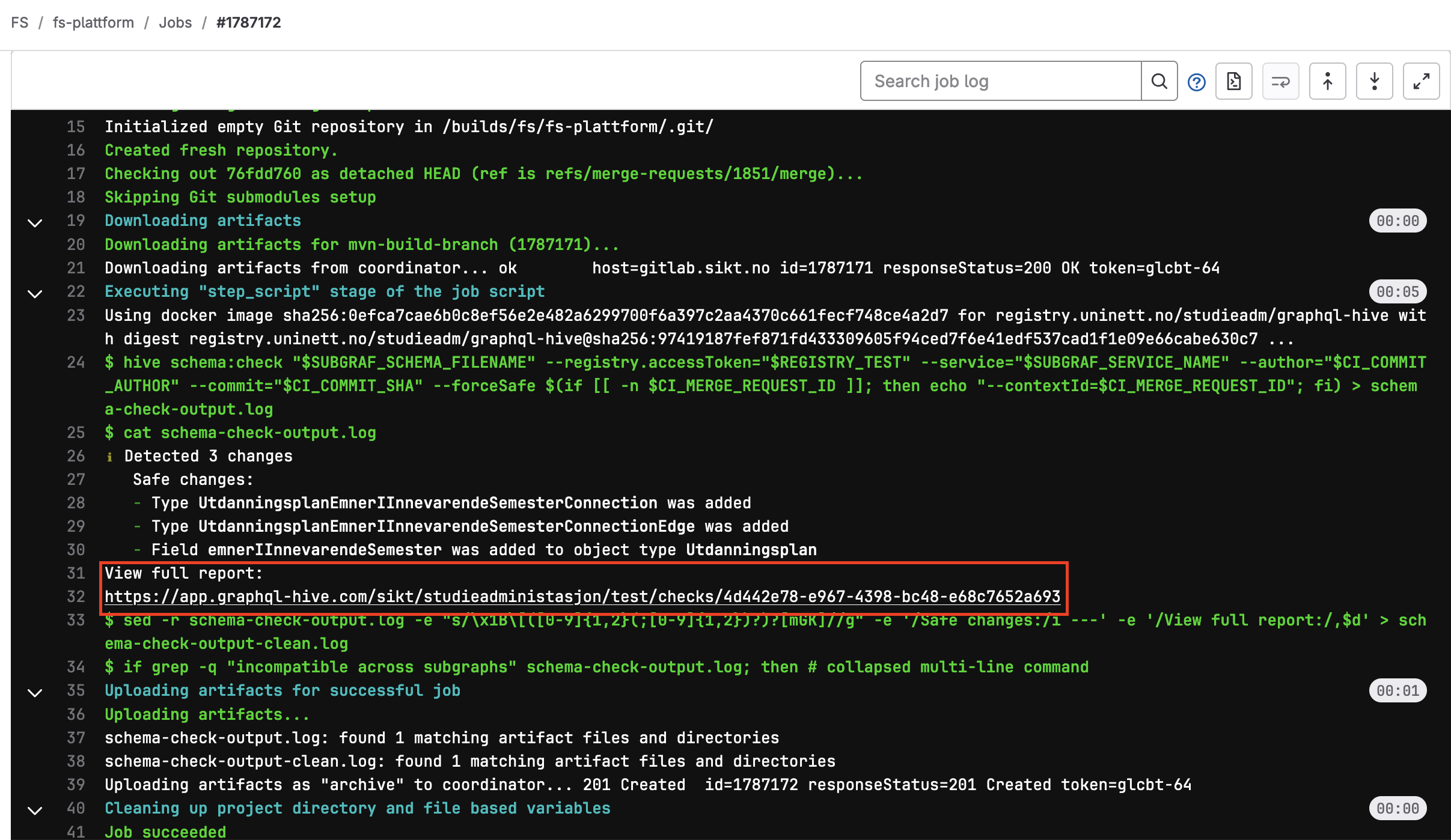
*) Det kreves Hive-bruker for å se dette. Hive støtter SSO, så vi kommer til å se på muligheten for å integrere dette dersom det blir ønskelig.
2. Publisering av subgrafskjema til supergraf
Når MR-en merges til main må vi sørge for at skjemaendringen blir publisert til Hive - schema registry. Dette gjøres ved å inkludere jobber i pipeline som publiserer skjemaendringene til de ulike miljøene i Hive. Det vil typisk være ulike regler for når skjemaet skal publiseres til de ulike miljøene. Jobben som publiserer skjemaet til et gitt miljø må settes til å være avhengig av at jobben som deployer applikasjonen/subgrafen til samme miljø er ferdig, slik at skjemaet ikke blir publisert før subgrafen er deployet med de nye endringene.
Supergrafen blir automatisk oppdatert med endringene etter disse er publisert. Dette er en viktig del av prosessen for å sikre at konsumentene av supergrafen alltid har tilgang til oppdatert skjema.
Autentisering og tilgangsstyring
Alle forespørsler til supergrafen må være autentisert, og tilgangen styres likt uavhengig av hvilken
subgraf dataene kommer fra. Supergrafen autentiserer forespørselen og veksler den eksterne
autentiseringen inn i et internt, signert token – ved hjelp av en coprocessor – som subgrafene
bruker for å håndheve tilgangsregler i databasene sine. Det interne tokenet sendes til subgrafene i
headeren supergraph-authorization, og skal aldri eksponeres til applikasjoner.
Hvordan dette fungerer i detalj – coprocessoren, det interne JWT-et, tilgangsmodellen, og hvorfor all tilgangsstyring skjer fra produksjon uavhengig av miljø – er beskrevet på den egne siden om tilgangsstyring.